Host open-source LLMs on local machines
This note demonstrates how to initiate an endpoint with FastChat for local LLM application in AutoGen.
We only use FastChat here for hosting LLMs. However, it could also be used for training, and evaluating LLMs.
Preparation
Install FastChat with pip.
pip3 install "fschat[model_worker,webui]"
Some tutorials also recommend to clone FastChat from github, but it seems not work for me. After cloning the repository, I cannot start the server (controller).
Now create a directory for your project and download the model checkpoint or import from Hugging Face. I deployed vicuna-7b from Hugging Face repo.
Initiate Server
First, launch controller:
python -m fastchat.serve.controller
Then, launch model worker(s):
python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.5
Finally, launch the RESTful API server:
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
Revise OpenAI config in AutoGen
According to the user guidence of OpenAI AutoGen, we are not supposed to reveal our API keys. In this case, I would like to revise the OAI_CONFIG_LIST. However, since this model is host locally, you can also write the config in your code.
[
\\ Other model configs
{
"model": "vicuna-7b-v1.5",
"base_url": "http://localhost:8000/v1",
"api_type": "openai",
"api_key": "NULL"
}
]
More facts about FastChat
FastChat Web UI
The fastchat.serve.controller is used to serve the models with Web UI provided by FastChat. However, since I only use it for hosting my models, while running the controller, you may get multiple errors in your terminal. Don’t be panic, it’s totally normal, they won’t hamper you from hosting the models.
If you are interested, here is an illustration for FastChat web server architecture I borrowed from their github repo.
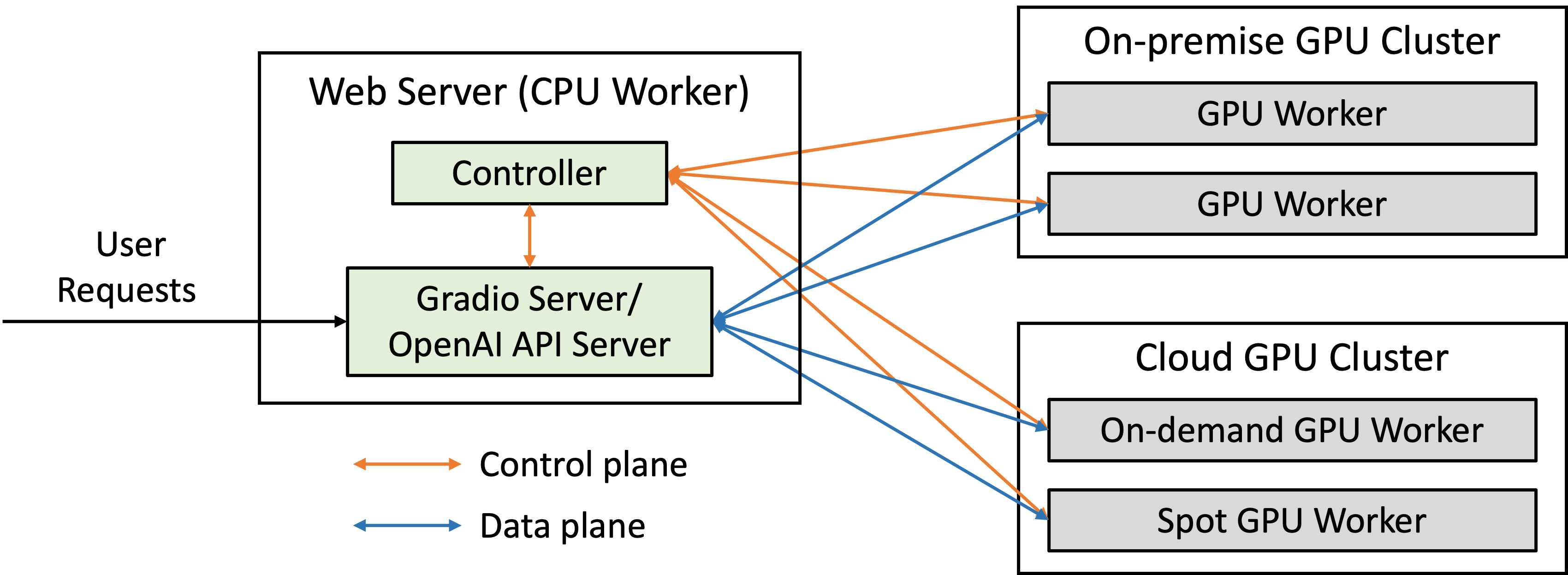
FastChat Web Server Architecture
FastChat Command Line Interface (CLI)
Apart from the Web UI, they also provide CLI, fastchat.serve.cli. For example, you can run vicuna-7b in your terminal:
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5
If you have multiple GPUs (say, 2 GPUs in the example command) on the same machine, run the following command to make full use of your GPUs:
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.5 --num-gpus 2