Database
Two approach to store data
File based Approach
Problems with the file-based approach
- Definition of data was embeded into the application programs, rather than being stored separately and independently
- No control over access and manipulation of data beyond that imposed by application programs
Disadvantages to the file-based approach
- Separation and isolation of data
- Duplication of data
- Dependence between the application and the data store
- Incompatible file formats
- Programs are written to satisfy one specific data request
Database Approach
Problems with the database approach
- All data is pooled together, some data might not be shared with others
Database View
- Allows each user to have his or her own definition of the database
- A view provides access to a subset of the database
- View mechanism is imperative if we want to secure the data
Benefits
- Reduce complexity
- Provides a level of security
- Provides a mechanism to customize the appearance of the database
- Present a consistent, unchanging picture of the structure of the database, even when the underlying structure og the database has changed
Database
- A database can be defined as a collection of logically related data from which users can efficiently retrieve the desired information.
- System catalog (metadata) provides description of data to enable program’s data independence.
- A Database Management System (DBMS) is an integrated set of programs used to create and maintain a database. The main objective of a DBMS is to provide a convenient and effective method of defining, storing, retrieving, and manipulating the data contained in the database.
- The main advantage of DBMS is centralized data management.
- Redundancy: Represents a relationship between two objects in a relational database.
Benefits
- Control of data redundancy
- data consistency
- More information from the same amount of data
- Sharing of data
- Improved data integrity
- Improved security
- Enforcement of standards
- Economy of scale
- Balance conflicting requirements
- Improved data accessibility and responsiveness
- Increased productivity
- Improved maintenance through data independence
- Increased concurrency
- Improved backup and recovery services
Drawbacks
- Complexity
- Size
- Cost of DBMS
- Additional hardware costs
- Cost of converting your data to a database
- Performance can degrade since time increases size of data
- Higher impact of a failure
Roles of database user
- Data Administrator (DA)
- Database Administrator (DBA)
- Database Designers (Logical and Physical)
- Application Programmers
- End Users (naive and sophisticated)
Database Architechtures
- Old Architechtures
- Teleprocessing
- File Server Architecture
Client-Server Architecture
- default architecture used to build modern day databases
- In the client server architecture, the database application is spread across at lease two different processes, residing on potentially two different platforms.
- Identify the functionality that the client would need to provide for a database application
- Identify the functionality that the database server would need to provide for a database application
Server and Client Functionality
| Client | Server |
|---|---|
| Manages the user interface | Accepts and processes database requests from clients |
| Accepts and checks syntax of user input | Checks authorization |
| Processes application logic | Ensures integrity constrains not violated |
| Generates database requests and transmits to server | Performs query/update processing and transmits response to client |
| Passes response back to user | Maintains system catalog;Provides concurrent database access;Provides recovery control |
3-Tier (3-schema) Database applications (ANSI/SPARC architecture)
- Internal level (has Internal schema): It is the lowest level of data abstraction that deals with the physical representation of the database on the computer and thus, is also known as physical level. It describes how the data is physically stored and organized on the storage medium. At this level, various aspects are considered to achieve optimal runtime performance and storage space utilization. These aspects include storage space allocation techniques for data and indexes, access paths such as indexes, data compression and encryption techniques, and record placement.
- Conceptual level (has Conceptual schema): This level of abstraction deals with the logical structure of the entire database and thus, is also known as logical level. It describes what data is stored in the database, the relationships among the data and complete view of the user’s requirements without any concern for the physical implementation. That is, it hides the complexity of physical storage structures. The conceptual view is the overall view of the database and it includes all the information that is going to be represented in the database.
- External level (has External schemas / user views): It is the highest level of abstraction that deals with the user’s view of the database and thus, is also known as view level. In general, most of the users and application programs do not require the entire data stored in the database. The external level describes a part of the database for a particular group of users. It permits users to access data in a way that is customized according to their needs, so that the same data can be seen by different users in different ways, at the same time. In this way, it provides a powerful and flexible security mechanism by hiding the parts of the database from certain users, as the user is not aware of existence of any attributes that are missing from the view.
The process of transforming the requests and results between various levels of DBMS architecture is known as mapping.
The main advantage of three-schema architecture is that it provides data independence.
Data independence is the ability to change the schema at one level of the database system without having to change the schema at the other levels.
- Logical data independence
- Physical data independence
Benefits
- ‘Thin’ Client, requires less expensive hardware.
- Application maintaince centralized.
- Easier to modify or replace one tier without affecting others.
- Separates business logic from database functions, making it easier to implement load balancing.
- Maps quite naturally to Web environment.
Transaction Processing Monitor (TPM)
- middleware runs on application server
Tasks provided by a TPM
- Transaction routing to different database servers
- transaction monitoring for distributed transactions
- Load balancing for client requests across duplicated servers
- Funneling - that allows the TPM to connect users to the DB when they need data and disconnect them when another user requests the connection.
- The TP monitor can increase reliability provided by the system by recognizing node failure and redirecting the query to another similar node that can answer the question.
Conceptual Data Modeling
Conceptual / Semantic Modelling
- A conceptual data model is a definition of the information objects of a domain
- Information (data) modeling is the process of describing information structures and capturing rules and constraints
- Data models are described using a visual notation supported by text narratives and other artifacts
Visualizing Multiplicity
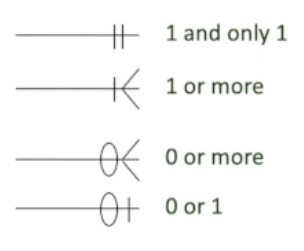
Visualizing Multiplicity
Visualizing data models
- Domain Model
- Entities (Classes)
- Attributes
- Relationships
- [Keys & Identifiers]
- Identify entities: nouns in conversations
- Identify relationships: nouns connected by verbs
- verbs become the relationships
- degree of the relationship = number of entities that are related
- Attributes of Entities
- An attribute is a property of an entity
- Composite attribute: an attribute that is formed by combining related attributes
- Single attribute: atomic or simple attribute
- Multivalued attribute: has more than one value for a single attribute
- derived attribute: has a value that can be computed from the values of other attributes
- Key attribute: a unique identifier distinguishes every entity occurrence.
- Primary key
- Foreign key
- Alternate key
- Attribute Domain
- The domain of an attribute is athe set of legal values that an attribute can have
- Domains can be defined without tying ourselves to implementation details
- Common Domain Types: NUMBER, TEXT, MEMO (larger, indeterminable size TEXT), DATE, TIME, BOOLEAN, VALUE SET, IMAGE.
- The relationship between 2 entities has an associated multiplicity
- Cardinality: is often the number of occurrences of an entity (sometimes consider the same as multiplicity)
Entity-Relationship Diagram
- Entity-Relationship (ER) diagrams are also commonly used for data modeling
- Why choose UML over ER
- UML can easily represent data lifecycle
- ER complexity: multiple “levels” and “notations”
- ER Diagram Level
- Conceptual: entities, relationships
- Logical: entities, relationships, attributes
- Physical: entities, relationships, attributes, data types
UML (Unified Modeling Language)
Multiplicity
- n..m (n<=m; n,m>=0)
- Unbounded (*). Cannot come alone.
Class Diagram
- Use to express a conceptual data model that is implementation and database agnostic
- a collection or set of another entity: unfilled diamond
System Analysis Approach
Enterprise Analysis -> Requirements Analysis -> Conceptual Data Modeling -> Logical Data Modeling -> Physical Database Design
Requirements Analysis contains:
- Use case Analysis
- Prototyping and RAD
Phases of Data Modeling
- Conceptual Data Modeling
- Logical Data Modeling
- Physical Database Design
Modeling & Systems Analysis
Two model types are generally constructed
- Static Model (structure diagrams)
- focuses on data not process
- data and object model
- Dynamic Model (behavior diagrams)
- focuses on processes not data
- process and use case model
Relationship Types
association (relationship between instances)
Straight line
- An association is a simple semetic relationship between two entities that indicates a link between them.
- The relationship between two entities has an associated multiplicity
- a lower bound of 0 indicates an optionality
generalization (relationship between classes)
non-filled arrow
- An us-a relationship that identifies similarities and differences
- Subclass Justification
Aggregation
- An aggregation is a special kind of association where one class is part of another class (non-filled diamond)
- Composition is a special form of aggregation where the part objects are permanently part of the container (filled-diamond)
Relational Model
-
Generallu databases are based on one of the three models
- Hierachical model
- Network model
- Relational model
-
Relational model include 3 components
- Structural component
- Manipulative component
- Integrity constraints
-
Basic of Relational Model
- The relational model represents both data and the relationships among those data using relations.
- A relation is used to represent information about any entity (such as book, publisher, author, etc.) and its relationship with other entities in the form of attributes (or columns) and tuples (or rows).
- A relation is comprised of a relation schema and a relation instance.
- A relation schema (relation intension) defines the attributes of a table.
- A relation instance (relation extension) is a two-dimensional table with a time-varying set of tuples.
Relation Schema
- A relation schema consists of a relation name and a set of attributes (or fields)

relation schema
- The set of permissible value of same data type for an attribute is termed as the domain of that attribute
- The data type or format for each domain is the physical definition of domains
- the value of the domain is the logical definition of domains
- Domain can be unstructured and structured
- Unstructured (or atomic) domain: consists of the non-decomposable or indivisible values that cannot be further divided into sub-values
- structured (or composite) domain: consists of non-atomic values that are decomposable or divisible values
Relation Instance
-
A relation instance (or relation) r of the relation schema R(A1, A2, …, An) is a set of n-tuples t, It is also denoted by r(R)
-
Properties of Relations
- The number of attributes in a relation is known as its degree or arity.
- The number of tuples in a relation is referred to as the relation’s cardinality.
- Since a relation is a set of tuples and a set is unordered, tuples in a relation do not have any specific order.
Characteristics of Relations
-
Ordering of Tuples in a Relation: tuples in a relation do not have any specified order. However, tuples in a relation can be logically ordered by the values of various attributes.
-
Values and Nulls in the Tuples:
- The relational model assumes that the tuples in a relational contain atomic values, i.e., each A~i~ is a single value from its domain D~i~
- A relation does not allow composite and multivalued attributes
- A non-existent or unknown value of an attribute is denoted as null
-
No two tuples can be identical in a relation
Relational Database Schema
- A set of relation schemas together with a set of integrity constraints in the database constitutes relational database schema
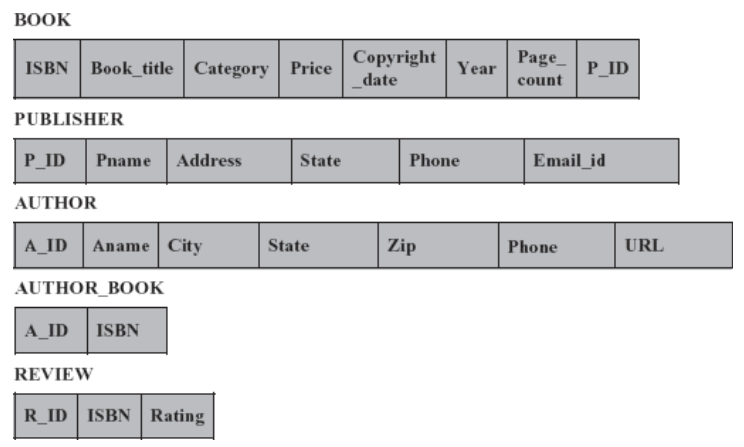
Relational Database Schema
Keys
Superkey
The combination of attributes in superkey uniquely identify each tuple in the relation state r
For example, consider a relation schema BOOK with three attributes ISBN, Book_title, and Category. As we know, the value of ISBN is unique for each tuple; hence, {ISBN} is a superkey. In addition, the combination of all the attributes, that is, {ISBN, Book_title, Category} is a default superkey for this relation schema.
Candidate key
If any attribute is removed from the superkey subset, the remaining set of attributes can no longer serve as a superkey. Such a minimal set of attributes is a candidate key (also known as irreducible superkey)
For example, the superkey {ISBN, Book_title, Category} is not a candidate key, since its subset {ISBN} is a minimal set of attributes that uniquely identify each tuple of BOOK relation. So, ISBN is a candidate key.
Primary Key
A candidate key that is chosen to uniquely identify a tuple in a relation is known as primary key. Other candidate keys that are not chosen as primary key are known as alternate keys.
Foreign key
Attribute of one relation can be accessed in another relation by enforcing a link between the attributes of two relations. This can be done by defining the attribute of one relation as the foreign key that refers to the primary key of another relation.
Relation DB Creation
- Fundamental Structure: Table
Database Integrity
Domain Integrity
- Domain Integrity is applied on the attribute and requires that every attribute A~i~ is a value from its domain D~i~
Entity Integrity
- Entity integrity defines restrictions on the tuples of a relation which ensures the accuracy and consistency of the database.
- It requires that each tuple in a realation is unique
- The primary key must be a set of attributes that cannot have duplicate values or be null
- primary key must be
- unique
- not reusable
- unchangable
- void of semantic meaning
- invisible to the user
Referential Integrity
- Foreign keys establish links between tables
- A foreign key must “point” to an existing row with that primary key
Semantic Integrity
- Semantic Integrity ensures that business and other logical rules are enforced
Relational Table Rules
- All rows are formatted identically
- Rows are unsorted
- Columns are in no particular order
- Each row in a table is a unique instance
- There are no duplicate column (attribute) names
- Within the table, values represent data
- Each column (attribute) value is atomic
- Primary keys should be non-compound and minimal
Normalization & Normal Forms
- Normalization is required when a database is not properly designed through data modeling
- The most common is the “spreadsheet design” approach that many database designers use: lump all data into a single table like a spreadsheet
- A database that suffers from Spreadsheet Syndrome is subject to numerous data redundancies, data anomalies and is generally inefficient.
Approach to Database Design: Top-Down Approach
- Start with a conceptual model based on grouping attributes into their natural entities
- Generally BCNF(Boyce-Code Normal Form) is sufficient
- Well designed conceptual models are generally in BCNF
- Transactional databases should be normalized but Analytical databases should not
Normal Forms
- Normal Forms are progressive
- Decomposition is at the heart of normalization
- Attribute preservation property of decomposition
Rules for Decomposition
- For small databases, it may be possible for a database designer to decompose a relation schema through inspection.
- For large, complex database schemas, a direct decomposition is difficult as there can be multiple ways in which a relational schema can be decomposed.
- To determine whether a relation schema should be decomposed, and which relation schema may be better than another, a formal methodology is needed.
Normal forms provide the guidelines and function dependencies provide the method by which to decompose.